










』開発者合同インタビュー。「Pay to Winにはしない」「4度の失敗を経ての挑戦」など決意みなぎる")



』は、「本格派」と「カジュアル派」を両方巻き込むマルチ対戦ロボアクションの予感。体験会で見せたそのポテンシャル")















米カリフォリニア大学サンディエゴ校の音楽科およびコンピュータ・サイエンス科の研究チームは22日、ディープラーニングを応用して音楽ゲーム『Dance Dance Revolution』(以下、DDR)の譜面を自動生成するアルゴリズムに関する論文を発表した。オープンソース音楽ゲーム『StepMania』のコミュニティから取り込んだ膨大なサンプルデータを基に、どの部分でどの矢印をどう配置するかのパターンを学習し、ユーザーが入力した生音源のデータから2種類のニューラルネットワークを用いて譜面を自動生成するという内容だ。そのプロセスの一部から名付けられた「Dance Dance Convolution」(以下、DDC)という論文のタイトルが、ソーシャルメディアを中心に脚光を浴びている。
反復可能な方法論としては初
ディープラーニングとは、多層構造のニューラルネットワーク(脳機能の特性をコンピュータによるシミュレーションで表現する数学モデルのこと、近年では神経科学と区別するため人工ニューラルネットワークとも呼ばれる)を応用した機械学習を指す。代表的なモデルとして、畳み込みニューラルネットワーク(通称、CNN=Convolutional Neural Networks)や再帰型ニューラルネットワーク(通称、RNN=Recurrent Neural Network)などが挙げられる。音声認識や画像解析、障害物センサーといった物体認識など様々な分野に応用されており、近年ではGoogle傘下のDeepMind社が開発した人工知能「AlphaGo」が囲碁の世界チャンピオンに勝利したことでも衆目を集めた。
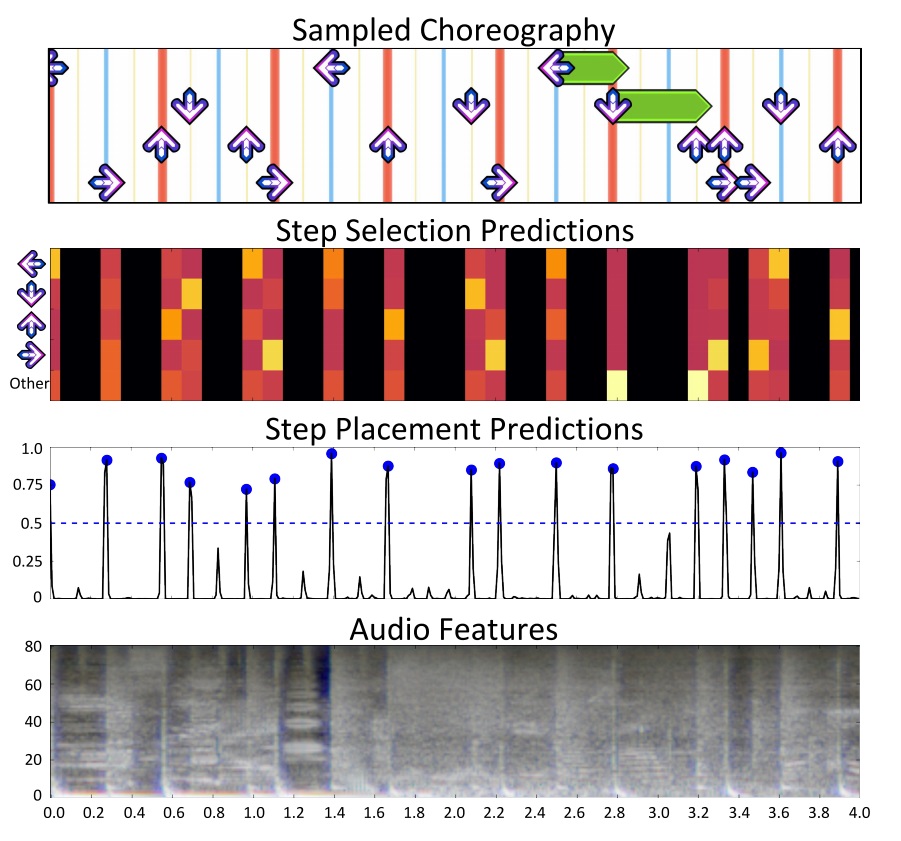 『DDR』の譜面作成に必要な情報は主に2つ。楽曲のどの部分で矢印が出るか。そして「←」「↑」「→」「↓」といった矢印に、同時押し(ジャンプ)と長押し(フリーズ)を組み合わせたステップが、どのようなパターンで出現するかだ。自動生成アルゴリズムを作成するには、その法則を決定する膨大なサンプルデータが必要になる。幸運にも『StepMania』(DDRやPump It Up、ParaParaParadise、Pop’n musicといった音楽ゲームをシミュレートできるオープンソースのソフトウェア)のコミュニティには、ユーザーが独自に作成した膨大な楽曲の譜面データが公開されている。ちなみに「DDR」の譜面作成に関する研究は過去にも複数の論文が発表されているが、データに基づいたセマンティクス学習や反復可能な方法論の確立は「DDC」が初めての試みである。
『DDR』の譜面作成に必要な情報は主に2つ。楽曲のどの部分で矢印が出るか。そして「←」「↑」「→」「↓」といった矢印に、同時押し(ジャンプ)と長押し(フリーズ)を組み合わせたステップが、どのようなパターンで出現するかだ。自動生成アルゴリズムを作成するには、その法則を決定する膨大なサンプルデータが必要になる。幸運にも『StepMania』(DDRやPump It Up、ParaParaParadise、Pop’n musicといった音楽ゲームをシミュレートできるオープンソースのソフトウェア)のコミュニティには、ユーザーが独自に作成した膨大な楽曲の譜面データが公開されている。ちなみに「DDR」の譜面作成に関する研究は過去にも複数の論文が発表されているが、データに基づいたセマンティクス学習や反復可能な方法論の確立は「DDC」が初めての試みである。
「DDC」の譜面学習に使われているサンプルデータは、『StepMania』ユーザーFraxtil氏が作成した90曲分の譜面と、同ゲームエンジンを利用した別作品『In The Groove』に収録されているコレクション133曲分。計9人が作成した譜面1102件だ。楽曲ファイルは全部で7時間におよび、難易度別の譜面をすべてつなげるとおよそ35時間分になる。そのステップ数は約35万個。その内84パーセントは単体の矢印によるものだったという。そこから主に拍子・時間・ステップの情報を抽出して、後述する「ステップ設置」のアルゴリズムに利用している。なお、「DDR」の譜面は難易度が上がるほどステップの密度が増す。ビギナーレベルではほとんど4分音符と8分音符だけだが、上級者向けになると16分音符や3連音符を用いたより複雑なステップが刻まれる。
ステップが設置できるのは1小節につき192箇所あるが、各6ステップが平均とされている。このままでは長期フレームにおけるパターンを確立するにはばらつきがあり過ぎるため、譜面学習のタスクを2つに分ける必要が出てくる。そこで採用されているのが、CNNを使った「ステップ設置」とRNNによる「ステップ選択」だ。学術的な記述は割愛するが、大雑把に説明すると、前者は生音源を取り込んでステップごとのタイムスタンプを予想するアルゴリズム。後者は連続するステップの確率分布をモデル化することで、矢印の種類と組み合わせをマッピングしてくれるアルゴリズムだ。そのため、同じ楽曲を再度入力した場合、ステップ数に変化はないがシークエンスの出力は毎回異なる結果になる。入力音源の位相解析には短時間フーリエ変換を用いている。
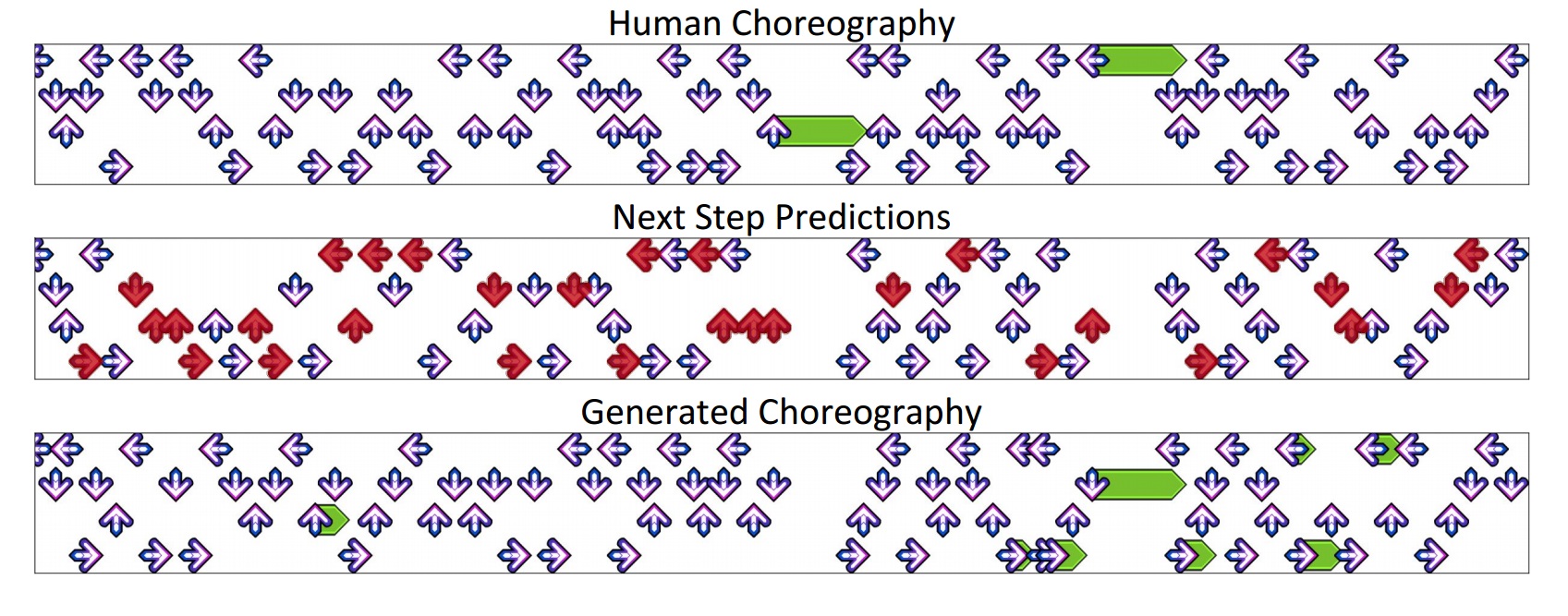 この論文を基に作成された実際の「DDC」はウェブ上に公開されており、『Stepmania 5』をインストールしていれば誰でも利用できる。任意のオーディオファイル(16MBが上限)を参照して、「ビギナー」「イージー」「ミディアム」「ハード」「チャレンジ」から難易度を選択するだけで、「DDR」の譜面が瞬時にできあがる。なお、前述したとおり低難易度ではステップ密度が低いことから、現状では十分な精度が得られない。一方で高密度の譜面では、LSTM(Long Short-Term Memoryの略、RNNの拡張で過去の入力から未来の入力を予測する役割を担う)モデルで生成された譜面が、サンプルとして使われている手動生成の譜面に限りなく近いことが確認できる。今後の改良で低難易度の譜面生成における精度の向上も期待される。
この論文を基に作成された実際の「DDC」はウェブ上に公開されており、『Stepmania 5』をインストールしていれば誰でも利用できる。任意のオーディオファイル(16MBが上限)を参照して、「ビギナー」「イージー」「ミディアム」「ハード」「チャレンジ」から難易度を選択するだけで、「DDR」の譜面が瞬時にできあがる。なお、前述したとおり低難易度ではステップ密度が低いことから、現状では十分な精度が得られない。一方で高密度の譜面では、LSTM(Long Short-Term Memoryの略、RNNの拡張で過去の入力から未来の入力を予測する役割を担う)モデルで生成された譜面が、サンプルとして使われている手動生成の譜面に限りなく近いことが確認できる。今後の改良で低難易度の譜面生成における精度の向上も期待される。


開催へ")








